Welcome back to the Abstract!
Sad news: the marriage between the Milky Way and Andromeda may be off, so don’t save the date (five billion years from now) just yet.
Then: the air you breathe might narc on you, hitchhiking worm towers, a long-lost ancient culture, Assyrian eyeliner, and the youngest old fish of the week.
An Update on the Fate of the Galaxy
Sawala, Till et al. “No certainty of a Milky Way–Andromeda collision.” Nature Astronomy.
Our galaxy, the Milky Way, and our nearest large neighbor, Andromeda, are supposed to collide in about five billion years in a smashed ball of wreckage called “Milkomeda.” That has been the “prevalent narrative and textbook knowledge” for decades, according to a new study that then goes on to say—hey, there’s a 50/50 chance that the galacta-crash will not occur.
What happened to The Milkomeda that Was Promised? In short, better telescopes. The new study is based on updated observations from the Gaia and Hubble space telescopes, which included refined measurements of smaller nearby galaxies, including the Large Magellanic Cloud, which is about 130,000 light years away.
Astronomers found that the gravitational pull of the Large Magellanic Cloud effectively tugs the Milky Way out of Andromeda’s path in many simulations that incorporate the new data, which is one of many scenarios that could upend the Milkomeda-merger.
“The orbit of the Large Magellanic Cloud runs perpendicular to the Milky Way–Andromeda orbit and makes their merger less probable,” said researchers led by Till Sawala of the University of Helsinki. “In the full system, we found that uncertainties in the present positions, motions and masses of all galaxies leave room for drastically different outcomes and a probability of close to 50% that there will be no Milky Way–Andromeda merger during the next 10 billion years.”
“Based on the best available data, the fate of our Galaxy is still completely open,” the team said.
Wow, what a cathartic clearing of the cosmic calendar. The study also gets bonus points for the term “Galactic eschatology,” a field of study that is “still in its infancy.” For all those young folks out there looking to get a start on the ground floor, why not become a Galactic eschatologist? Worth it for the business cards alone.
In other news…
The Air on Drugs
Nousias, Orestis, McCauley, Mark, Stammnitz, Maximilian et al. “Shotgun sequencing of airborne eDNA achieves rapid assessment of whole biomes, population genetics and genomic variation.” Nature Ecology & Evolution.
Living things are constantly shedding cells off into their surroundings where it becomes environmental DNA (eDNA), a bunch of mixed genetic scraps that provide a whiff of the biome of any given area. In a new study, scientists who captured air samples from Dublin, Ireland, found eDNA from plenty of humans, pathogens, and drugs.
“[Opium poppy] eDNA was also detected in Dublin City air in both the 2023 and 2024 samples,” said researchers led by co-led by Orestis Nousias and Mark McCauley of the University of Florida, and Maximilian Stammnitz of the Barcelona Institute of Science and Technology. “Dublin City also had the highest level of Cannabis genus eDNA” and “Psilocybe genus (‘magic mushrooms’) eDNA was also detectable in the 2024 Dublin air sample.”
Even the air is a snitch these days. Indeed, while eDNA techniques are revolutionizing science, they also raise many ethical concerns about privacy and surveillance.
Catch a Ride on the Wild Worm Tower
Perez, Daniela et al. “Towering behavior and collective dispersal in Caenorhabditis nematodes.” Current Biology.
The long wait for a wild worm tower is finally over. I know, it’s a momentous occasion. While scientists have previously observed tiny worms called nematodes joining to form towers in laboratory conditions, this Voltron-esque adaptation has now been observed in a natural environment for the first time.
 Images show a) A tower of worms. b) A tower explores the 3D space with an unsupported arm. c) A tower bridges an ∼3 mm gap to reach the Petri dish lid d) Touch experiment showing the tower at various stages. Image: Perez, Daniela et al.
Images show a) A tower of worms. b) A tower explores the 3D space with an unsupported arm. c) A tower bridges an ∼3 mm gap to reach the Petri dish lid d) Touch experiment showing the tower at various stages. Image: Perez, Daniela et al.
“We observed towers of an undescribed Caenorhabditis species and C. remanei within the damp flesh of apples and pears” in orchards near the University of Konstanz in Germany, said researchers led by Daniela Perez of the Max Planck Institute of Animal Behavior. “As these fruits rotted and partially split on the ground, they exposed substrate projections—crystalized sugars and protruding flesh—which served as bases for towers as well as for a large number of worms individually lifting their bodies to wave in the air (nictation).”
According to the study, this towering behavior helps nematodes catch rides on passing animals, so that wave is pretty much the nematode version of a hitchhiker’s thumb.
A Lost Culture of Hunter-Gatherers
Krettek, Kim-Louise et al. “A 6000-year-long genomic transect from the Bogotá Altiplano reveals multiple genetic shifts in the demographic history of Colombia.” Science Advances.
Ancient DNA from the remains of 21 individuals exposed a lost Indigenous culture that lived in Colombia’s Bogotá Altiplano in Colombia for millennia, before vanishing around 2,000 years ago.
These hunter-gatherers were not closely related to either ancient North American groups or ancient or present-day South American populations, and therefore “represent a previously unknown basal lineage,” according to researchers led by Kim-Lousie Krettek of the University of Tübingen. In other words, this newly discovered population is an early branch of the broader family tree that ultimately dispersed into South America.
“Ancient genomic data from neighboring areas along the Northern Andes that have not yet been analyzed through ancient genomics, such as western Colombia, western Venezuela, and Ecuador, will be pivotal to better define the timing and ancestry sources of human migrations into South America,” the team said.
The Eyeshadow of the Ancients
Amicone, Silvia et al. “Eye makeup in Northwestern Iran at the time of the Assyrian Empire: a new kohl recipe based on manganese and graphite from Kani Koter (Iron Age III).” Archaeometry.
People of the Assyrian Empire appreciated a well-touched smokey eye some 3,000 years ago, according to a new study that identified “kohl” recipes used for eye makeup from an Iron Age cemetery Kani Koter in Northwestern Iran.
 Makeup containers at the different sites. Image: Amicone, Silvia et al.
Makeup containers at the different sites. Image: Amicone, Silvia et al.
“At Kani Koter, the use of natural graphite instead of carbon black testifies to a hitherto unknown kohl recipe,” said researchers led by Silvia Amicone of the University of Tübingen. “Graphite is an attractive choice due to its enhanced aesthetic appeal, as its light reflective qualities produce a metallic appearance.”
Add it to the ancient lookbook. Both women and men wore these cosmetics; the authors note that “modern assumptions that cosmetic containers would be gender-specific items aptly highlight the limitations of our present understanding of the wider cultural and social contexts of the use of eye makeup during the Iron Age in the Middle East.”
New Onychodontid Just Dropped
Goodchild, Owen et al. “A new onychodontid (Osteichthyes, Sarcopterygii) from the Upper Devonian (Frasnian) of Devon Island, Nunavut Territory, Canada.” The Journal of Vertebrate Paleontology.
We’ll end with an introduction to Onychodus mikijuk, the newest member of a fish family called onychodontids that lived about 370 million years ago. The new species was identified by fragments found in Nunavut in Canada, including tooth “whorls” that are like little dental buzzsaws.
“This new species is the first record of an onychodontid from the Upper Devonian of the Canadian Arctic, the first from a riverine environment, and one of the youngest occurrences of the clade,” said researchers led by Owen Goodchild of the American Museum of Natural History.
Ah, to be 370-million-years-young again! Welcome to the fossil record, Onychodus mikijuk.
Thanks for reading! See you next week.
From 404 Media via this RSS feed



 404 MediaSamantha Cole
404 MediaSamantha Cole
 404 MediaSamantha Cole
404 MediaSamantha Cole


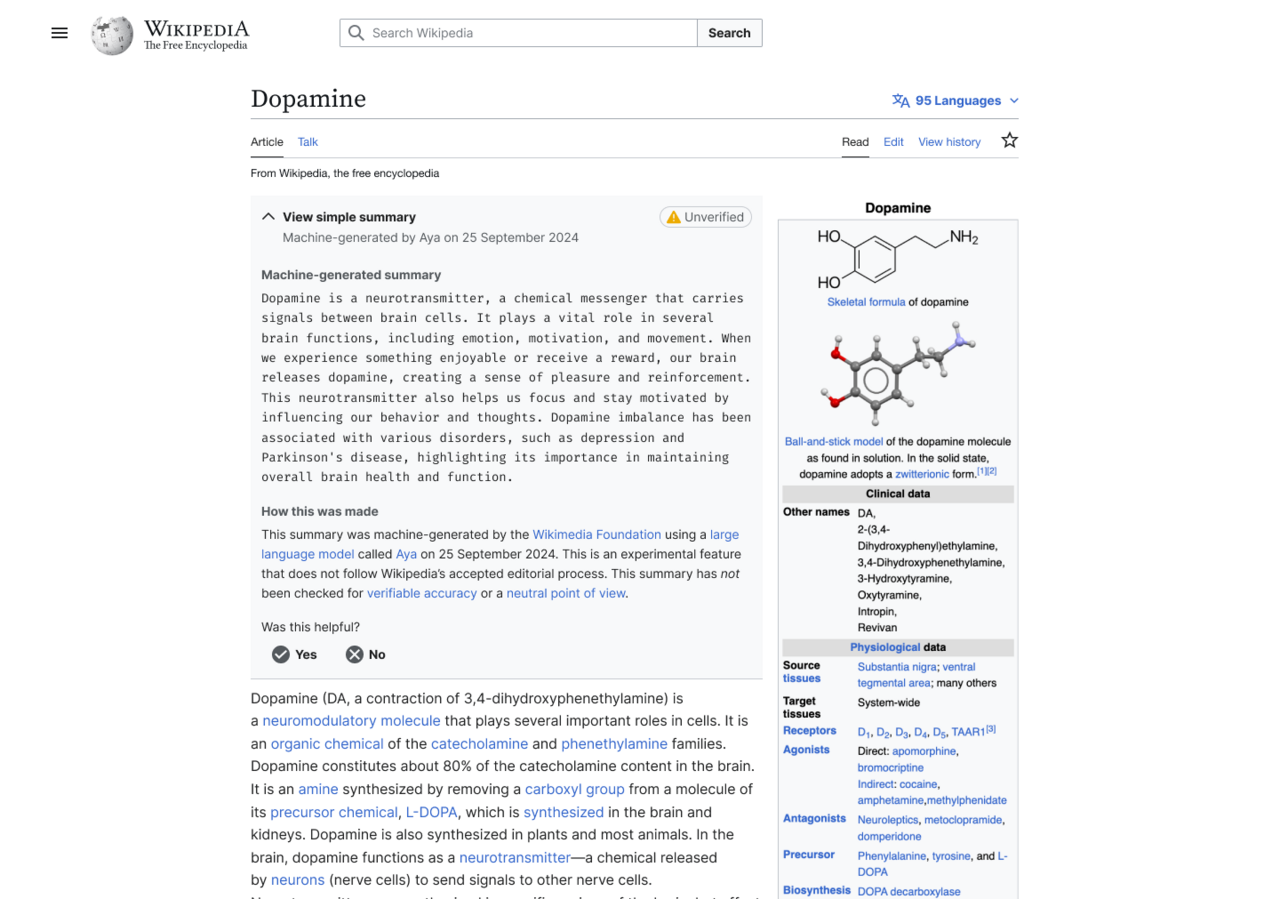 An example of what the AI-generated summary looked like.
An example of what the AI-generated summary looked like.



 Screenshot of the "Vaccine Hub" homepage on the es.vaccines.gov domain.
Screenshot of the "Vaccine Hub" homepage on the es.vaccines.gov domain. Screenshot of Google with the AI Overview result showing wrong information about cat cafes, taken from the AI spam blogs.
Screenshot of Google with the AI Overview result showing wrong information about cat cafes, taken from the AI spam blogs.




 404 MediaSamantha Cole
404 MediaSamantha Cole




 A chat with a "BadMomma" chatbot on AI Studio
A chat with a "BadMomma" chatbot on AI Studio A chat with a "mafia CEO" chatbot on AI Studio
A chat with a "mafia CEO" chatbot on AI Studio




 Left:
Left: 
 A screenshot from the patent application that shows a diagram of virtual hands roaming over a person's body
A screenshot from the patent application that shows a diagram of virtual hands roaming over a person's body A screenshot from the patent application that explains how a "Haptic Feedback Algorithm" would map a person's body
A screenshot from the patent application that explains how a "Haptic Feedback Algorithm" would map a person's body Diagram of smiling man wearing a haptic feedback glove
Diagram of smiling man wearing a haptic feedback glove A drawing of the haptic feedback glove
A drawing of the haptic feedback glove