1
Free Open-Source Artificial Intelligence
3578 readers
1 users here now
Welcome to Free Open-Source Artificial Intelligence!
We are a community dedicated to forwarding the availability and access to:
Free Open Source Artificial Intelligence (F.O.S.A.I.)
More AI Communities
LLM Leaderboards
Developer Resources
GitHub Projects
FOSAI Time Capsule
- The Internet is Healing
- General Resources
- FOSAI Welcome Message
- FOSAI Crash Course
- FOSAI Nexus Resource Hub
- FOSAI LLM Guide
founded 2 years ago
MODERATORS
2
3
1
[HELP] In GPT4All settings, selecting AMD graphics card yields no performance improvement over CPU
(lemmy.ml)
Background: This Nomic blog article from September 2023 promises better performance in GPT4All for AMD graphics card owners.
Run LLMs on Any GPU: GPT4All Universal GPU Support
Likewise on GPT4All's GitHub page.
September 18th, 2023: Nomic Vulkan launches supporting local LLM inference on NVIDIA and AMD GPUs.
Problem: In GPT4All, under Settings > Application Settings > Device, I've selected my AMD graphics card, but I'm seeing no improvement over CPU performance. In both cases (AMD graphics card or CPU), it crawls along at about 4-5 tokens per second. The interaction in the screenshot below took 174 seconds to generate the response.
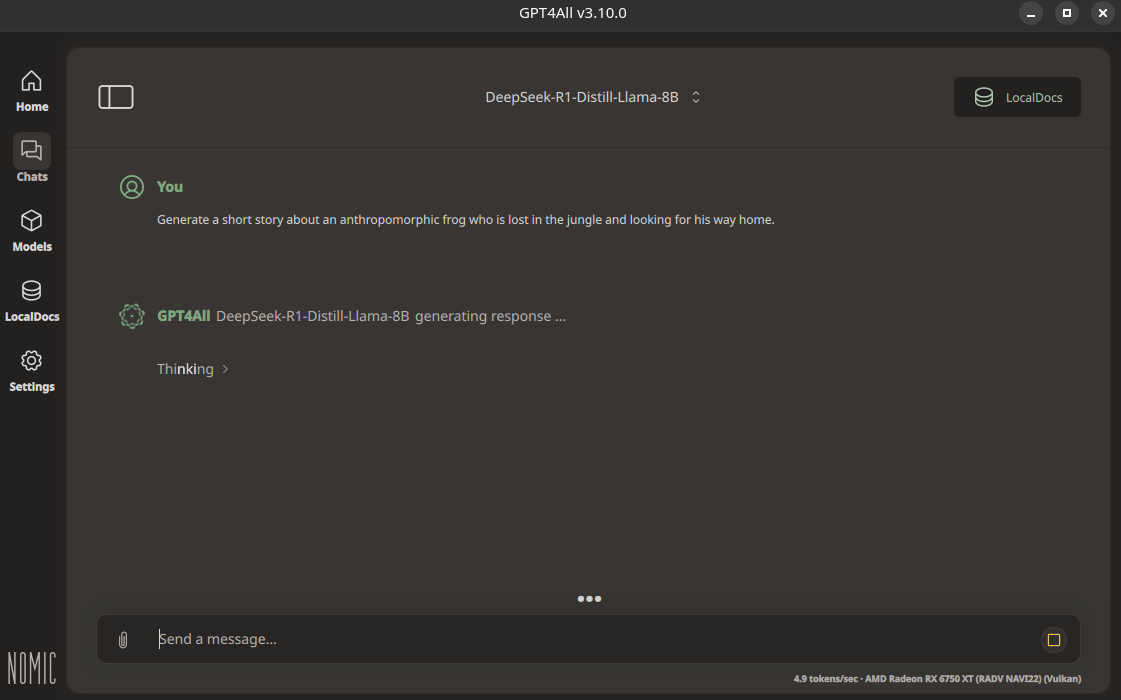
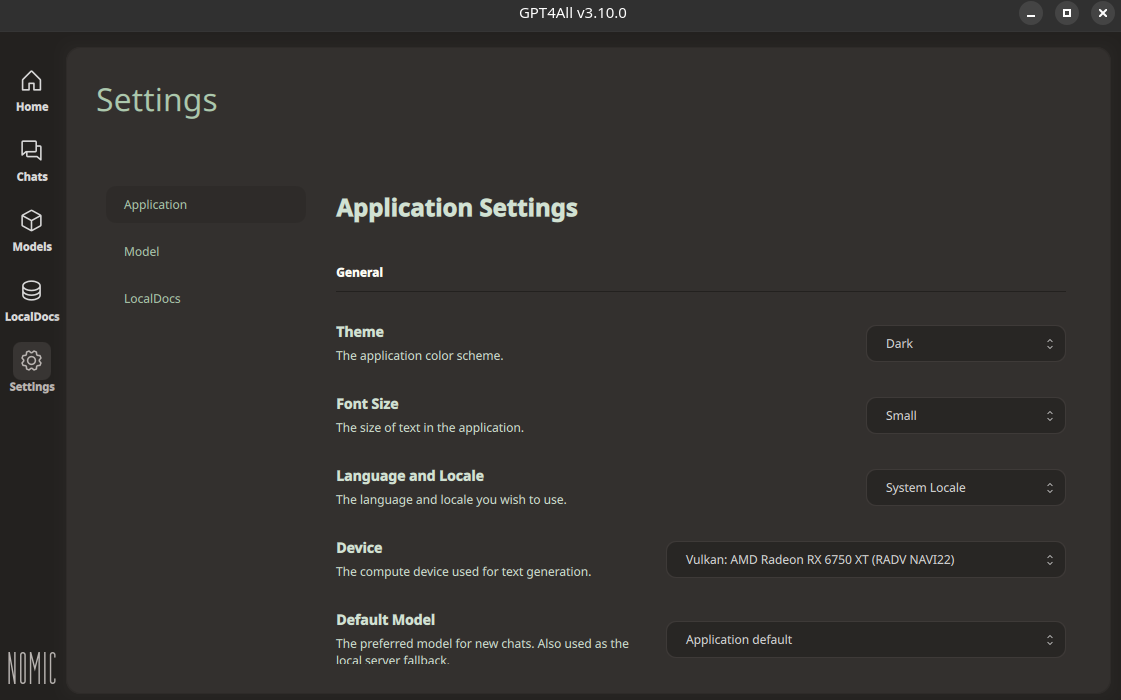
Question: Do I have to use a specific model to benefit from this advancement? Do I need to install a different AMD driver? What steps can I take to troubleshoot this?
Sorry if this is an obvious question. Sometimes I feel like the answer is right in front of me, but I'm unsure of which key words from the documentation should jump out at me.
My system info:
- GPU: Radeon RX 6750 XT
- CPU: Ryzen 7 5800X3D processor
- RAM: 32 GB @ 3200 MHz
- OS: Linux Bazzite
- I've installed GPT4All as a flatpak
5
6
7
8
9
10
11
12
13
1
FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
(fantasy-amap.github.io)
14
15
16
17
18
19
20
21
22
23
24
25
view more: next ›