51
Technology
1139 readers
20 users here now
A tech news sub for communists
founded 2 years ago
MODERATORS
52
53
1
Chinese doctors perform ‘remote surgeries’ thousands of kilometers from patients using a high-speed satellite
(peertube.mesnumeriques.fr)
54
55
56
57
1
Chinese Team Applies AI in Dynamic Control of Industrial Fermentation Process
(www.yicaiglobal.com)
58
59
60
61
1
China's "drone + firefighting" provides a new solution for high-rise building fires
(peertube.mesnumeriques.fr)
62
63
64
65
66
67
1
AI headphones translate multiple speakers at once, cloning their voices in 3D sound
(www.washington.edu)
68
69
70
71
72
73
74
75
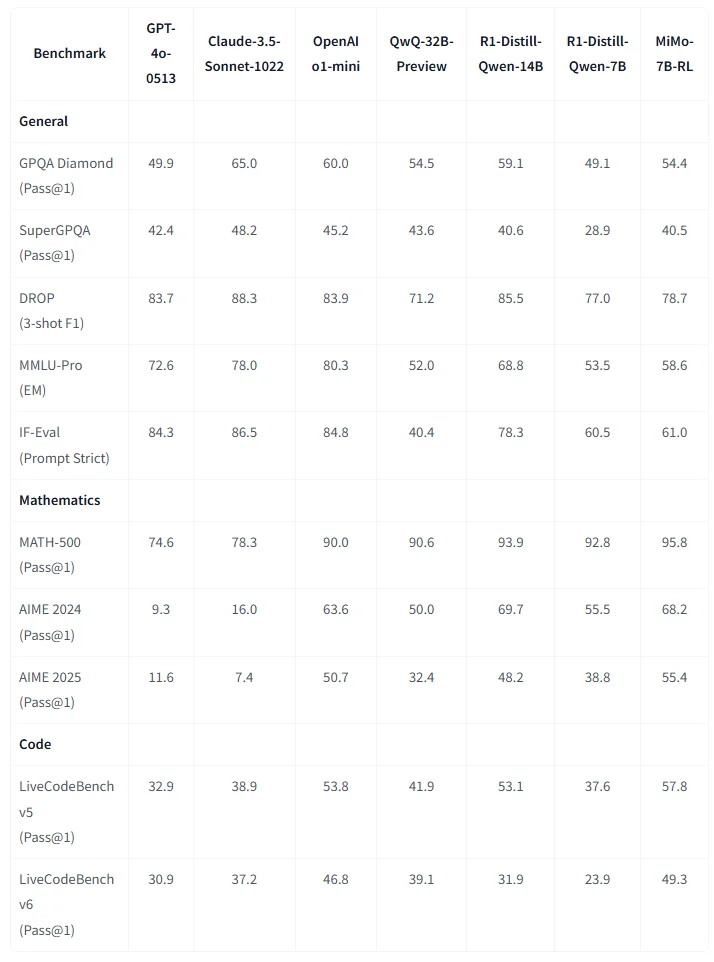
MiMo-7B, a series of reasoning-focused language models trained from scratch, demonstrating that small models can achieve exceptional mathematical and code reasoning capabilities, even outperforming larger 32B models. Key innovations include:
- Pre-training optimizations: Enhanced data pipelines, multi-dimensional filtering, and a three-stage data mixture (25T tokens) with Multiple-Token Prediction for improved reasoning.
- Post-training techniques: Curated 130K math/code problems with rule-based rewards, a difficulty-driven code reward for sparse tasks, and data re-sampling to stabilize RL training.
- RL infrastructure: A Seamless Rollout Engine accelerates training/validation by 2.29×/1.96×, paired with robust inference support. MiMo-7B-RL matches OpenAI’s o1-mini on reasoning tasks, with all models (base, SFT, RL) open-sourced to advance the community’s development of powerful reasoning LLMs.
an in-depth discussion of mimo-7b https://www.youtube.com/watch?v=y6mSdLgJYQY